Articolele lui
 Omer Genan (genan)
Omer Genan (genan)
Integrarea prin formula lui Simpson
Vom calcula valoarea unei integrale definite
\( \int_a ^ b f (x) dx \)
Soluția descrisă aici a fost publicată într-una dintre disertațiile lui Thomas Simpson în 1743.
Formula lui Simpson
Fie \(n\) un număr natural oarecare. Împărțim segmentul de integrare \([a, b]\) în \(2n\) părți egale:
\(x_i = a + i h, ~~ i = 0 \ldots 2n,\)
\(h = \frac {b-a} {2n}.\)
Deci, să presupunem că luăm în considerare următorul segment \([x_ {2i-2}, x_ {2i}], i = 1 \ldots n\) . Înlocuim funcția \(f(x)\) pe el cu o parabolă \(P(x)\) care trece prin 3 puncte \((x_ {2i-2}, x_ {2i-1}, x_ {2i}, x_ {2i})\) . O astfel de parabolă există întotdeauna și este unică; ea poate fi găsită analitic. De exemplu, am putea să o construim folosind interpolarea polinomială Lagrange. Singurul lucru care rămâne de făcut este să integrăm acest polinom. Dacă faceți acest lucru pentru o funcție generală \(f\) , veți obține o expresie remarcabil de simplă:
\(\int_{x_ {2i-2}} ^ {x_ {2i}} f (x) ~dx \approx \int_{x_ {2i-2}} ^ {x_ {2i}} P (x) ~dx = \left(f(x_{2i-2}) + 4f(x_{2i-1})+(f(x_{2i})\right)\frac {h} {3}\)
Adăugând aceste valori pe toate segmentele, obținem formula finală a lui Simpson:
\(\int_a ^ b f (x) dx \approx \left(f (x_0) + 4 f (x_1) + 2 f (x_2) + 4f(x_3) + 2 f(x_4) + \ldots + 4 f(x_{2N-1}) + f(x_{2N}) \right)\frac {h} {3}\)
Eroare
Eroarea de aproximare a unei integrale prin formula lui Simpson este
\(-\tfrac{1}{90} \left(\tfrac{b-a}{2}\right)^5 f^{(4)}(\xi)\)
unde \(\xi\) este un număr oarecare între \(a\) și \(b\).
Eroarea este asimptotic proporțională cu \((b-a)^5\) . Cu toate acestea, derivatele de mai sus sugerează o eroare proporțională cu \((b-a)^4\) . Regula lui Simpson capătă un ordin în plus deoarece punctele în care se evaluează integrala sunt distribuite simetric în intervalul \([a, b]\)
Implementare
Aici, \(f(x)\) este o funcție definită de utilizator.
const int N = 1000 * 1000; // numărul de pași (deja înmulțit cu 2)
double simpson_integration(double a, double b){
double h = (b - a) / N;
double s = f(a) + f(b); // a = x_0 and b = x_2n
for (int i = 1; i <= N - 1; ++i) { // Se referă la formula finală a lui Simpson
double x = a + h * i;
s += f(x) * ((i & 1) ? 4 : 2);
}
s *= h / 3;
return s;
} Omer Genan (genan)
Omer Genan (genan) Algoritmul euclidian extins
În timp ce algoritmul euclidian calculează doar cel mai mare divizor comun (GCD) a două numere întregi și , versiunea extinsă găsește, de asemenea, o modalitate de a reprezenta GCD în termeni de a și b, adică coeficienții x și y pentru care:
\( a \cdot x + b \cdot y = \gcd(a, b) \)
Este important de reținut că putem găsi întotdeauna o astfel de reprezentare, de exemplu \( \gcd(55, 80) = 5 \) prin urmare, putem reprezenta 5 ca o combinație liniară cu termenii 55 și 80: \( 55 \cdot 3 + 80 \cdot (-2) = 5 \)
Algoritmul
În această secțiune vom nota GCD-ul lui a și b cu g.
Modificările aduse algoritmului original sunt foarte simple. Dacă ne amintim algoritmul, putem vedea că acesta se termină cu \( b = 0 \) și \( a=g \). Pentru acești parametri putem găsi cu ușurință coeficienți, și anume \( g\cdot 1 + 0 \cdot 0 = g \).
Pornind de la acești coeficienți \( (x, y) = (1, 0) \), putem merge înapoi în sus în apelurile recursive. Tot ce trebuie să facem este să ne dăm seama cum se schimbă coeficienții și în timpul tranziției de la \( (a, b)) \), la \( (b, a \bmod b) \) .
Să presupunem că am găsit coeficienții \((x_1, y_1) \) pentru \((b, a \bmod b) \):
\(b \cdot x_1 + (a \bmod b) \cdot y_1 = g \)
și dorim să găsim perechea \((x, y) \) pentru \((a, b) \) :
\(a \cdot x + b \cdot y = g \)
Putem reprezenta \(a \bmod b\) sub forma:
\(a \bmod b = a – \left\lfloor \frac{a}{b} \right\rfloor \cdot b\)
Înlocuind această expresie în ecuația coeficientului din \((x_1, y_1)\) se obține:
\(g = b \cdot x_1 + (a \bmod b) \cdot y_1 = b \cdot x_1 + \left(a – \left\lfloor \frac{a}{b} \right\rfloor \cdot b \right) \cdot y_1)\)
și după rearanjarea termenilor:
\(g = a \cdot y_1 + b \cdot \left( x_1 – y_1 \cdot \left\lfloor \frac{a}{b} \right\rfloor \right)\)
Am găsit valorile lui x și y:
\(\begin{cases}
x = y_1 \\
y = x_1 – y_1 \cdot \left\lfloor \frac{a}{b} \right\rfloor
\end{cases}\)
Implementare
int gcd(int a, int b, int& x, int& y) {
if (b == 0) {
x = 1;
y = 0;
return a;
}
int x1, y1;
int d = gcd(b, a % b, x1, y1);
x = y1;
y = x1 - y1 * (a / b);
return d;
}
Funcția recursivă de mai sus returnează GCD și valorile coeficienților pentru x și y (care sunt transmise prin referință la funcție).
Această implementare a algoritmului euclidian extins produce rezultate corecte și pentru numere întregi negative.
Codul Gray
Codul Gray este un sistem numeric binar în care două valori succesive diferă doar printr-un singur bit.
De exemplu, secvența de coduri Gray pentru numere de 3 biți este: 000, 001, 011, 010, 110, 111, 101, 100, deci \( G(4) = 6 \)
Acest cod a fost inventat de Frank Gray în 1953.
Găsirea codului Gray
Să ne uităm la biții numărului \( n \) și la biții numărului \( G(n) \). Observați că al i-lea bit al numărului \( G(n) \) este egal cu 1 numai atunci când al i-lea bit al lui n este egal cu 1 și al i+1-lea bit este egal cu 0 sau invers (al i-lea bit este egal cu 0 și al i+1-lea bit este egal cu 1). Astfel, \( G(n) = n \oplus (n >> 1) \):
int g (int n) {
return n ^ (n >> 1);
}
Găsirea codului Gray invers
Dat fiind codul Gray g, restabiliți numărul original n.
Ne vom deplasa de la biții cei mai semnificativi la cei mai puțin semnificativi (bitul cel mai puțin semnificativ are indicele 1, iar bitul cel mai semnificativ are indicele k). Relația dintre biții \( n_i \) din numărul \( n \) și biții \( g_i \) din numărul \( g \):
\(\begin{align}
n_k &= g_k, \\
n_{k-1} &= g_{k-1} \oplus n_k = g_k \oplus g_{k-1}, \\
n_{k-2} &= g_{k-2} \oplus n_{k-1} = g_k \oplus g_{k-1} \oplus g_{k-2}, \\
n_{k-3} &= g_{k-3} \oplus n_{k-2} = g_k \oplus g_{k-1} \oplus g_{k-2} \oplus g_{k-3},
\vdots
\end{align}\)
Cel mai simplu mod de a o scrie în cod este:
int rev_g (int g) {
int n = 0;
for (; g; g >>= 1)
n ^= g;
return n;
}
Aplicații practice
Codurile Gray au câteva aplicații utile, uneori chiar neașteptate:
- Codul Gray de n biți formează un ciclu Hamiltonian pe un hipercub, unde fiecare bit corespunde unei dimensiuni.
- Codurile Gray sunt utilizate pentru a minimiza erorile în conversia semnalelor digitale în analogice (de exemplu, în cazul senzorilor).
- Codul Gray poate fi folosit pentru a rezolva problema Turnurilor din Hanoi. Fie \( n \) numărul de discuri. Se începe cu un cod Gray de lungime \( n \) care constă în toate zerourile (\( G(0) \)) și se trece de la un cod Gray consecutiv (de la \( G(i)\) la \( G(i+1) \)). Fie că al i-lea bit al codului Gray curent reprezintă al n-lea disc (bitul cel mai puțin semnificativ corespunde celui mai mic disc și bitul cel mai semnificativ celui mai mare disc). Deoarece la fiecare pas se schimbă exact un bit, putem considera că schimbarea celui de-al i-lea bit reprezintă deplasarea celui de-al i-lea disc. Observați că există exact o opțiune de mutare pentru fiecare disc (cu excepția celui mai mic) la fiecare pas (cu excepția pozițiilor de început și de sfârșit). Există întotdeauna două opțiuni de mutare pentru cel mai mic disc, dar există o strategie care va conduce întotdeauna la un răspuns: dacă n este impar, atunci secvența de mutare a celui mai mic disc arată ca \( f \to t \to r \to f \to t \to r \to … \) unde \( f \) este tija inițială, \( t \) este tija finală și \( r \) este tija rămasă), iar dacă este par: \( f \to r \to t \to f \to r \to t \to … \).
- Codurile Gray sunt, de asemenea, utilizate în teoria algoritmilor genetici.
Descompunerea in factori primi
În acest articol enumerăm mai mulți algoritmi de factorizare a numerelor întregi, fiecare dintre ei putând fi atât rapid, cât și lent (unii mai lenți decât alții), în funcție de datele de intrare.
Observați că, dacă numărul pe care doriți să îl factorizați este de fapt un număr prim, majoritatea algoritmilor, în special algoritmul de factorizare al lui Fermat, algoritmul p-1 al lui Pollard, algoritmul rho al lui Pollard vor funcționa foarte lent. Prin urmare, este logic să efectuați un test de primalitate probabilistic (sau determinist rapid) înainte de a încerca să factorizați numărul.
Folosind definitia
Acesta este cel mai simplu algoritm de bază pentru a găsi o descompunere in factori primi.
Împărțim cu fiecare divizor posibil d. Putem observa că este imposibil ca toți factorii primi ai unui număr compus să fie mai mari decât \( \sqrt{n} \) . Prin urmare, trebuie doar să testăm divizorii \( 2 \le d \le \sqrt{n}\), ceea ce ne oferă factorizarea primilor în \( O(\sqrt{n})\).
Cel mai mic divizor trebuie să fie un număr prim. Îndepărtăm factorul din număr și repetăm procesul. Dacă nu putem găsi niciun divizor în intervalul \( [2; \sqrt{n}]\), atunci numărul în sine trebuie să fie prim.
vector<long long> trial_division1(long long n) {
vector<long long> factorization;
for (long long d = 2; d * d <= n; d++) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
if (n > 1)
factorization.push_back(n);
return factorization;
}
Factorizarea roată
Aceasta este o optimizare a variantei in care folosim definitia. Ideea este următoarea. Odată ce știm că un număr nu este divizibil cu 2, nu mai este nevoie să verificăm fiecare alt număr par. Acest lucru ne lasă doar 50% din numere de verificat. După ce verificăm 2, putem pur și simplu să începem cu 3 și să sărim peste toate celelalte numere.
Această metodă poate fi extinsă. Dacă numărul nu este divizibil cu 3, putem ignora toți ceilalți multipli de 3 în calculele viitoare. Astfel, trebuie să verificăm doar numerele \( \5, 7, 11, 13, 17, 19, 23, \dots\) . Putem observa un model al acestor numere rămase. Trebuie să verificăm toate numerele cu \( \d \bmod 6 = 1\) și \( \d \bmod 6 = 5\). Astfel, ne rămân doar 33,3% din numere de verificat. Putem pune în aplicare acest lucru verificând mai întâi numerele prime 2 și 3, apoi putem începe verificarea cu 5 și alternativ să sărim 1 sau 3 numere.
Putem extinde acest lucru și mai mult. Iată o implementare pentru numerele prime 2, 3 și 5. Este convenabil să folosim o matrice pentru a stoca cât de mult trebuie să sărim.
vector<long long> trial_division3(long long n) {
vector<long long> factorization;
for (int d : {2, 3, 5}) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
static array<int, 8> increments = {4, 2, 4, 2, 4, 6, 2, 6};
int i = 0;
for (long long d = 7; d * d <= n; d += increments[i++]) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
if (i == 8)
i = 0;
}
if (n > 1)
factorization.push_back(n);
return factorization;
}
Dacă extindem acest lucru mai departe cu mai multe numere prime, putem ajunge chiar la procente mai bune. Cu toate acestea, și listele de sărituri vor deveni mult mai mari.
Prime precalculate
Extinderea factorizării roții cu din ce în ce mai multe numere prime va lăsa exact numerele prime de verificat. Așadar, o modalitate bună de verificare este de a calcula în prealabil toate numerele prime cu ciurul lui Eratosthenes până la \( \sqrt{n} \) și de a le testa individual.
vector<long long> primes;
vector<long long> trial_division4(long long n) {
vector<long long> factorization;
for (long long d : primes) {
if (d * d > n)
break;
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
if (n > 1)
factorization.push_back(n);
return factorization;
}
Metoda de descompunere in factori primi a lui Fermat
Putem scrie un număr compus impar \( n = p \cdot q\) ca diferență a două pătrate \( n = a^2 – b^2\):
\(n = \left(\frac{p + q}{2}\right)^2 – \left(\frac{p – q}{2}\right)^2\)
Metoda de descompunere in factori primi a lui Fermat încearcă să exploateze acest fapt, ghicind primul pătrat \( a^2\) și verificând dacă partea rămasă \( b^2 = a^2 – n\) este, de asemenea, un număr pătrat. Dacă este, atunci am găsit factorii \( a – b\) și \( a + b\) ai lui n.
int fermat(int n) {
int a = ceil(sqrt(n));
int b2 = a*a - n;
int b = round(sqrt(b2));
while (b * b != b2) {
a = a + 1;
b2 = a*a - n;
b = round(sqrt(b2));
}
return a - b;
}
Observați că această metodă de factorizare poate fi foarte rapidă, dacă diferența dintre cei doi factori p și q este mică. Algoritmul se execută în timp \( O(|p – q|)\). Cu toate acestea, deoarece este foarte lent, odată ce factorii sunt foarte depărtați, este rar utilizat în practică.
Cu toate acestea, există încă un număr mare de optimizări pentru această abordare. De exemplu, prin examinarea pătratelor \( a^2\) modulo un număr mic fix, puteți observa că nu trebuie să vă uitați la anumite valori a, deoarece acestea nu pot produce un număr pătrat \( a^2 – n\)
Numerele catalane
Numerele catalane reprezintă o secvență de numere, care se dovedește a fi utilă într-o serie de probleme combinatorii, care implică adesea obiecte definite recursiv.
Această secvență a fost numită după matematicianul belgian Catalan, care a trăit în secolul al XIX-lea. (De fapt, ea a fost cunoscută înainte de Euler, care a trăit cu un secol înaintea lui Catalan).
Primele numere catalane sunt(cu \(C_n\) si n incepand de la 0):
\(1, 1, 2, 5, 14, 42, 132, 429, 1430, \ldots\)
Aplicații în unele probleme de combinatorica
Numărul catalan \(C_n\) este soluția pentru:
- Numărul de secvențe de paranteze corecte formate din n paranteze de deschise și n paranteze de închise.
- Numărul de arbori binari cu rădăcina si n+1 frunze (vârfurile nu sunt numerotate). Un arbore binar înrădăcinat este complet dacă fiecare vârf are fie doi copii, fie niciun copil.
- Numărul de moduri de a pune complet între paranteze n+1 factori.
- Numărul de triangulații ale unui poligon convex cu n+2 laturi (adică numărul de împărțiri ale poligonului în triunghiuri disjuncte prin utilizarea diagonalelor).
- Numărul de moduri în care se pot lega cele 2n puncte de pe un cerc pentru a forma n coarde disjuncte.
- Numărul de arbori binari compleți neizomorfi cu n noduri interne (adică noduri care au cel puțin un fiu).
- Numărul de trasee monotone de rețea de la punctul (0, 0) la punctul (n, n) într-o rețea pătrată de dimensiune nxn, care nu trec deasupra diagonalei principale (adică (0, 0) care face legătura cu (n, n)).
- Numărul de permutări de lungime n care pot fi ordonate în stivă (adică se poate demonstra că rearanjarea este ordonată în stivă dacă și numai dacă nu există un astfel de indice i<j<k, astfel încât \(a_k < a_i < a_j\)).
- Numărul de partiții neîncrucișate ale unui set de n elemente.
- Numărul de moduri în care se poate acoperi scara \(1 \ldots n\) folosind n dreptunghiuri (scara este formată din n coloane, unde \(i^{th}\) coloana are înălțimea i).
Mod de calcul
Există două formule pentru numerele catalane: Recursivă și Analitică. Deoarece considerăm că toate problemele menționate mai sus sunt echivalente (au aceeași soluție), pentru demonstrarea formulelor de mai jos vom alege sarcina care este cel mai ușor de realizat.
Formulă recurentă
\(C_0 = C_1 = 1\)
\(C_n = \sum_{k = 0}^{n-1} C_k C_{n-1-k} , {n} \geq 2\)
Formula de recurență poate fi dedusă cu ușurință din problema secvenței corecte de paranteze.
Cea mai din stânga paranteză de deschidere l corespunde unei anumite paranteze de închidere r, care împarte secvența în 2 părți care, la rândul lor, ar trebui să fie o secvență corectă de paranteze. Astfel, formula este, de asemenea, împărțită în 2 părți. Dacă notăm \(k = {r – l – 1}\), atunci, pentru un r fix, vor exista exact \(C_k C_{n-1-k}\) astfel de secvențe de paranteze. Însumând acest lucru peste toate \(k’s\) admisibile, obținem relația de recurență pe \(C_n\),.
De asemenea, puteți gândi în felul următor. Prin definiție, \(C_n\) reprezintă numărul de secvențe de paranteze corecte. Acum, secvența poate fi împărțită în 2 părți de lungime k și n-k, fiecare dintre acestea trebuind să fie o secvență corectă de paranteze. Exemplu :
\(( ) ( ( ( ) )\) poate fi împărțit în () și (()), dar nu poate fi împărțit în ()( și ()). Însumând din nou peste toate \(k’s\) admisibile, obținem relația de recurență pe \(C_n\).
const int MOD = ....
const int MAX = ....
int catalan[MAX];
void init() {
catalan[0] = catalan[1] = 1;
for (int i=2; i<=n; i++) {
catalan[i] = 0;
for (int j=0; j < i; j++) {
catalan[i] += (catalan[j] * catalan[i-j-1]) % MOD;
if (catalan[i] >= MOD) {
catalan[i] -= MOD;
}
}
}
}
Formula analitică
\(C_n = \frac{1}{n + 1} {\binom{2n}{n}}\)
(aici \(\binom{n}{k}\) reprezintă coeficientul binomial obișnuit, adică numărul de moduri de a selecta k obiecte dintr-un set de n obiecte).
Formula de mai sus poate fi ușor de concluzionat din problema traseelor monotone în rețeaua pătrată. Numărul total de trasee monotone în rețeaua de dimensiuni nxn este dat de \(\\binom{2n}{n}\)
Acum numărăm numărul de trasee monotone care traversează diagonala principală. Considerăm astfel de traiectorii care traversează diagonala principală și găsim prima muchie din ea care se află deasupra diagonalei. Reflectăm traiectoria în jurul diagonalei până la capăt, mergând după această muchie. Rezultatul este întotdeauna o traiectorie monotonă în grila (n-1) x (n+1). Pe de altă parte, orice traiectorie monotonă în grila (n-1) x (n+1) trebuie să intersecteze diagonala. Prin urmare, am enumerat toate căile monotone care intersectează diagonala principală în rețeaua n x n.
Numărul de drumuri monotone în rețeaua (n-1) x (n+1) este \(\\binom{2n}{n-1}\) . Numim astfel de trasee “rele”. Ca urmare, pentru a obține numărul de trasee monotone care nu traversează diagonala principală, scădem traseele “rele” de mai sus, obținând formula:
\(C_n = \binom{2n}{n} – \binom{2n}{n-1} = \frac{1}{n + 1} \binom{2n}{n} , {n} \geq 0\)
Referinte:
- http://www.geometer.org/mathcircles/catalan.pdf
Găsirea puterii divizorului factorial
Vi se dau două numere n și k. Găsiți cea mai mare putere a lui k x astfel încât n! să fie divizibil cu \(k^x\).
Pentru k numar prim
Să luăm mai întâi în considerare cazul unui număr prim k. Expresia explicită pentru factorial: \(n! = 1 \cdot 2 \cdot 3 \ldots (n-1) \cdot n\)
Observați că fiecare al k-lea element al produsului este divizibil cu k, adică adaugă +1 la răspuns; numărul acestor elemente este \(\Bigl\lfloor\dfrac{n}{k}\Bigr\rfloor\)
Apoi, fiecare al \(k^2\)-lea element este divizibil cu \(k^2\), adică adaugă încă +1 la răspuns (prima putere a lui k a fost deja numărată în paragraful anterior). Numărul de astfel de elemente este \(\Bigl\lfloor\dfrac{n}{k^2}\Bigr\rfloor\).
Și așa mai departe, pentru fiecare i, fiecare al \(k^i\)-lea element adaugă încă +1 la răspuns, și există \(\Bigl\lfloor\dfrac{n}{k^i}\Bigr\rfloor\) astfel de elemente.
Răspunsul final este: \(\Bigl\lfloor\dfrac{n}{k}\Bigr\rfloor + \Bigl\lfloor\dfrac{n}{k^2}\Bigr\rfloor + \ldots + \Bigl\lfloor\dfrac{n}{k^i}\Bigr\rfloor + \ldots\).
Suma este, bineînțeles, finită, deoarece doar aproximativ primele \(\log_k n\) elementele nu sunt zero. Astfel, timpul de execuție al acestui algoritm este \(O(\log_k n)\).
Implementare
int fact_pow (int n, int k) {
int res = 0;
while (n) {
n /= k;
res += n;
}
return res;
}
Pentru un numar k compus
Aceeași idee nu poate fi aplicată direct. În schimb, se poate calcula un factor k reprezentat ca \(k = k_1^{p_1} \cdot \ldots \cdot k_m^{p_m}\)
Pentru fiecare \(k_i\), găsim numărul de ori de câte ori este prezent în n! folosind algoritmul descris mai sus – să numim această valoare \(a_i\). Răspunsul pentru numarul ka compus va fi:
\(\min_ {i=1 \ldots m} \dfrac{a_i}{p_i}\)
Teste de primalitate
Folosind definitia
Prin definiție, un număr prim nu are alți divizori decât 1 și el însăși. Un număr compus are cel puțin un divizor suplimentar, să îl numim d. Natural \(\frac{n}{d} \) va fi un divizor a lui n. Este ușor de văzut, că fied \(d \le \sqrt{n}\) sau \(\frac{n}{d} \le \sqrt{n}\), prin urmare, unul dintre divizorii d si \(\frac{n}{d} \) este \(d \le \sqrt{n}\). Putem folosi aceste informații pentru a verifica primalitatea.
Încercăm să găsim un divizor nenul, verificând dacă oricare dintre numerele cuprinse între 2 si \(\sqrt{n}\) sunt divizori ai lui n. Daca exista un divizor in acest interval, atunci este clar ca n nu este prim.
bool isPrime(int x) {
for (int d = 2; d * d <= x; d++) {
if (x % d == 0)
return false;
}
return true;
}
Aceasta este cea mai simplă formă de verificare a unei prime. Puteți optimiza destul de mult această funcție, de exemplu, verificând doar toate numerele impare în buclă, deoarece singurul număr prim par este 2.
Testul de primalitate Fermat
Acesta este un test probabilistic.
Mica teoremă a lui Fermat afirmă că, pentru un număr prim și un număr întreg coprim, este valabilă următoarea ecuație:
\(a^{p-1} \equiv 1 \bmod p\)
În general, această teoremă nu este valabilă pentru numerele compuse.
Aceasta poate fi utilizată pentru a crea un test de primalitate. Alegem un număr întreg \(2 \le a \le p – 2\) , și verificam dacă ecuația se confirmă sau nu. Dacă nu se menține, de ex. \(a^{p-1} \not\equiv 1 \bmod p\) , știm că nu poate fi un număr prim. În acest caz, numim baza un martor Fermat pentru compunerea lui p.
Cu toate acestea, este posibil ca ecuația să fie valabilă și pentru un număr compus. Deci, dacă ecuația este valabilă, nu avem o dovadă a primalității. Putem spune doar că p este probabil prim. Dacă se dovedește că numărul este de fapt compus, numim baza a un mincinos al lui Fermat.
Efectuând testul pentru toate bazele posibile a, putem demonstra că un număr este prim. Cu toate acestea, acest lucru nu se face în practică, deoarece acest lucru presupune un efort mult mai mare decât simpla efectuare a unei diviziuni de probă. În schimb, testul va fi repetat de mai multe ori cu alegeri aleatorii pentru a. Dacă nu găsim niciun martor al compunerii, este foarte probabil ca numărul să fie de fapt prim.
bool probablyPrimeFermat(int n, int iter=5) {
if (n < 4)
return n == 2 || n == 3;
for (int i = 0; i < iter; i++) {
int a = 2 + rand() % (n - 3);
if (binpower(a, n - 1, n) != 1)
return false;
}
return true;
}
Folosim Exponențierea binară pentru a calcula eficient puterea \(a^{p-1}\).
Există totuși o veste proastă: există unele numere compuse în care \(a^{n-1} \equiv 1 \bmod n\) este valabil pentru orice a coprim cu n, de exemplu pentru numărul \(561 = 3 \cdot 11 \cdot 17\). Astfel de numere se numesc numere Carmichael. Testul de primalitate Fermat poate identifica aceste numere doar dacă avem un noroc imens și alegem o bază a cu \(\gcd(a, n) \ne 1\).
Testul Fermat este încă utilizat în practică, deoarece este foarte rapid, iar numerele Carmichael sunt foarte rare. De exemplu, există doar 646 de astfel de numere sub \(10^9\).
Test de primalitate Miller-Rabin
Testul Miller-Rabin extinde ideile din testul Fermat.
Pentru un număr impar n, n-1 este par și putem elimina toate puterile lui 2. Putem scrie: \(n – 1 = 2^s \cdot d,~\text{with}~d~\text{odd}.\)
Acest lucru ne permite să factorizăm ecuația micii teoreme a lui Fermat:
\(\begin{array}{rl}
a^{n-1} \equiv 1 \bmod n &\Longleftrightarrow a^{2^s d} – 1 \equiv 0 \bmod n \\\\
&\Longleftrightarrow (a^{2^{s-1} d} + 1) (a^{2^{s-1} d} – 1) \equiv 0 \bmod n \\\\
&\Longleftrightarrow (a^{2^{s-1} d} + 1) (a^{2^{s-2} d} + 1) (a^{2^{s-2} d} – 1) \equiv 0 \bmod n \\\\
&\quad\vdots \\\\
&\Longleftrightarrow (a^{2^{s-1} d} + 1) (a^{2^{s-2} d} + 1) \cdots (a^{d} + 1) (a^{d} – 1) \equiv 0 \bmod n \\\\
\end{array}\)
Dacă n este prim, atunci n trebuie să împartă unul dintre acești factori. Iar în testul de primalitate Miller-Rabin verificăm exact această afirmație, care este o versiune mai strictă a afirmației din testul Fermat.Pentru o bază \(2 \le a \le n-2\) se verifică dacă fie: \(a^d \equiv 1 \bmod n2\) deține sau \(a^{2^r d} \equiv -1 \bmod n\) este valabil pentru un anumit \(0 \le r \le s – 1\)
Dacă am găsit o bază a care nu satisface niciuna dintre egalitățile de mai sus, atunci am găsit un martor al compunerii lui n.În acest caz am dovedit că n nu este un număr prim.
La fel ca în cazul testului lui Fermat, este posibil ca setul de ecuații să fie satisfăcut pentru un număr compus. În acest caz, baza a se numește un mincinos puternic. Dacă o bază a satisface ecuațiile (una dintre ele), este doar un prim puternic probabil. Cu toate acestea, nu există numere precum numerele Carmichael, unde se află toate bazele nenule. De fapt, este posibil să se arate că cel mult \(\frac{1}{4}\) din baze pot fi niște mincinoși puternici. Dacă n este compus, avem o probabilitate de \(\ge 75\%\) că o baza aleatorie ne va spune că este compusă. Făcând mai multe iterații, alegând diferite baze aleatoare, putem spune cu o probabilitate foarte mare dacă numărul este cu adevărat prim sau dacă este compus.
Iată o implementare pentru numere întregi pe 64 de biți.
using u64 = uint64_t;
using u128 = __uint128_t;
u64 binpower(u64 base, u64 e, u64 mod) {
u64 result = 1;
base %= mod;
while (e) {
if (e & 1)
result = (u128)result * base % mod;
base = (u128)base * base % mod;
e >>= 1;
}
return result;
}
bool check_composite(u64 n, u64 a, u64 d, int s) {
u64 x = binpower(a, d, n);
if (x == 1 || x == n - 1)
return false;
for (int r = 1; r < s; r++) {
x = (u128)x * x % n;
if (x == n - 1)
return false;
}
return true;
};
bool MillerRabin(u64 n, int iter=5) {
if (n < 4)
return n == 2 || n == 3;
int s = 0;
u64 d = n - 1;
while ((d & 1) == 0) {
d >>= 1;
s++;
}
for (int i = 0; i < iter; i++) {
int a = 2 + rand() % (n - 3);
if (check_composite(n, a, d, s))
return false;
}
return true;
}
Înainte de testul Miller-Rabin, puteți testa suplimentar dacă unul dintre primele câteva numere prime este un divizor. Acest lucru poate accelera foarte mult testul, deoarece majoritatea numerelor compuse au divizori primi foarte mici. De exemplu, 88% din toate numerele au un factor prim mai mic decât 100.
Versiunea deterministă
Miller a arătat că este posibil să se facă algoritmul determinist prin verificarea doar a tuturor bazelor \(\le O((\ln n)^2)\). Bach a dat mai târziu o limită concretă, este necesar doar să se testeze toate bazele \(a \le 2 \ln(n)^2\).
Acesta este încă un număr destul de mare de baze. Așadar, oamenii au investit destul de multă putere de calcul pentru a găsi limite inferioare. Se pare că, pentru testarea unui număr întreg de 32 de biți, este necesar să se verifice doar primele 4 baze prime: 2, 3, 5 și 7. Cel mai mic număr compus care nu trece acest test este \(3,215,031,751 = 151 \cdot 751 \cdot 28351\). Iar pentru testarea numerelor întregi de 64 de biți este suficient să se verifice primele 12 baze prime: 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31 și 37.
Aceasta duce la următoarea implementare deterministă:
bool MillerRabin(u64 n) {
if (n < 2)
return false;
int r = 0;
u64 d = n - 1;
while ((d & 1) == 0) {
d >>= 1;
r++;
}
for (int a : {2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37}) {
if (n == a)
return true;
if (check_composite(n, a, d, r))
return false;
}
return true;
}
De asemenea, este posibil să se facă verificarea cu numai 7 baze: 2, 325, 9375, 28178, 450775, 9780504 și 1795265022. Cu toate acestea, deoarece aceste numere (cu excepția lui 2) nu sunt prime, trebuie să verificați în plus dacă numărul pe care îl verificați este egal cu orice divizor prim al acestor baze: 2, 3, 5, 13, 19, 73, 193, 407521, 299210837.
COMPLEXITATEA DE TIMP A UNUI ALGORITM
În informatică, analiza algoritmilor este o parte foarte importantă. Este important să se găsească cel mai eficient algoritm pentru rezolvarea unei probleme. Este posibil să existe mai mulți algoritmi pentru a rezolva o problemă, dar provocarea aici este de a-l alege pe cel mai eficient.
Acum, întrebarea este cum putem recunoaște cel mai eficient algoritm dacă avem un set de algoritmi diferiți? Aici apare conceptul de complexitate în timp și spațiu a algoritmilor. Complexitatea spațială și temporală acționează ca o scală de măsurare a algoritmilor. Comparăm algoritmii pe baza complexității spațiale (cantitatea de memorie) și a complexității temporale (numărul de operații) a acestora.
Cantitatea totală de memorie a computerului utilizată de un algoritm atunci când este executat reprezintă complexitatea spațială a algoritmului respectiv. Nu vom discuta despre complexitatea spațială în acest articol
Complexitatea de timp
Astfel, complexitatea în timp reprezintă numărul de operații pe care un algoritm le efectuează pentru a-și îndeplini sarcina (considerând că fiecare operație durează același timp). Algoritmul care îndeplinește sarcina în cel mai mic număr de operații este considerat cel mai eficient din punct de vedere al complexității timpului. Cu toate acestea, complexitatea spațială și cea temporală sunt afectate și de factori precum sistemul de operare și hardware-ul, dar nu îi includem în această discuție.
Acum, pentru a înțelege complexitatea timpului, vom lua un exemplu în care vom compara doi algoritmi diferiți care sunt utilizați pentru a rezolva o anumită problemă.
Problema este căutarea. Trebuie să căutăm un element într-un tablou (în această problemă, vom presupune că tabloul este sortat în ordine crescătoare). Pentru a rezolva această problemă avem doi algoritmi:
*Cautare liniara
*Cautare binara
Să presupunem că tabloul conține zece elemente și că trebuie să găsim numărul zece în tablou.
const int array = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
const int search_digit = 10;
Algoritmul de căutare liniară va compara fiecare element al tabloului cu valoarea căutată. Dacă găsește valoarea căutată în tablou, va returna true.
Acum să numărăm numărul de operații pe care le efectuează. În acest caz, răspunsul este 10 (deoarece compară fiecare element al tabloului). Așadar, căutarea liniară utilizează zece operații pentru a găsi elementul dat (acesta este numărul maxim de operații pentru acest tablou; în cazul căutării liniare, acesta este cunoscut și ca fiind cel mai rău caz al unui algoritm).
În general, căutarea liniară va necesita un număr n de operații în cel mai rău caz (unde n este dimensiunea tabloului).
Să examinăm algoritmul de căutare binară pentru acest caz.
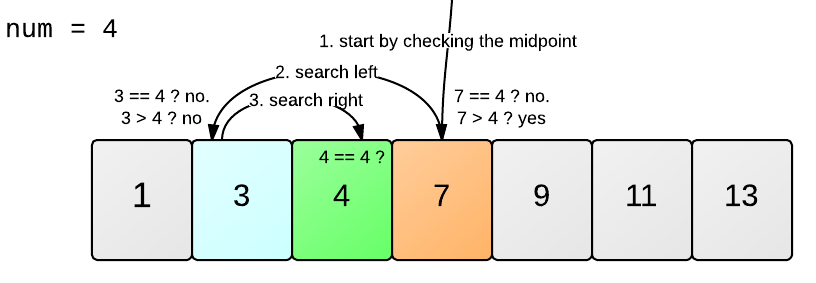
Căutarea binară poate fi ușor de înțeles prin acest exemplu
{kind=link}
Dacă încercăm să aplicăm această logică la problema noastră, atunci, mai întâi vom compara valoarea căutată cu elementul din mijloc al tabloului, adică 5. Acum, deoarece 5 este mai mic decât 10, vom începe să căutăm valoarea căutată în elementele tabloului mai mari decât 5, în același mod până când vom obține elementul dorit 10.
Acum, încercați să numărați numărul de operații de care a avut nevoie căutarea binară pentru a găsi elementul dorit. A fost nevoie de aproximativ patru operații. Acesta a fost cel mai rău caz pentru căutarea binară. Acest lucru arată că există o relație logaritmică între numărul de operații efectuate și dimensiunea totală a matricei.
numărul de operații = log(10) = 4(aproximativ)
pentru baza 2
Putem generaliza acest rezultat pentru căutarea binară astfel:
Pentru o matrice de dimensiune n, numărul de operații efectuate de căutarea binară este: log(n)
Notația Big O
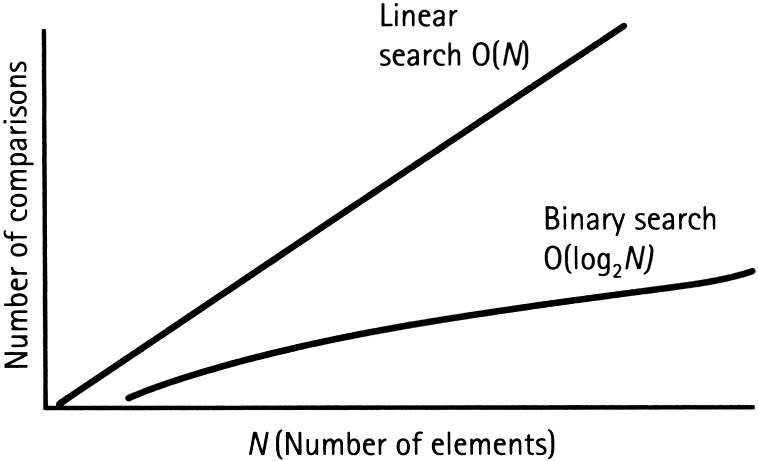
În afirmațiile de mai sus, am văzut că, pentru un tablou de dimensiune n, căutarea liniară va efectua n operații pentru a finaliza căutarea. Pe de altă parte, căutarea binară a efectuat un număr log(n) de operații (ambele pentru cel mai rău caz). Putem reprezenta acest lucru sub forma unui grafic (axa x: numărul de elemente, axa y: numărul de operații).
{kind=link}
Este destul de clar din figură că rata de creștere a complexității pentru căutarea liniară este mult mai rapidă decât cea pentru căutarea binară.
Atunci când analizăm un algoritm, folosim o notație pentru a reprezenta complexitatea în timp a acestuia, iar această notație este notația Big O.
De exemplu: complexitatea timpului pentru căutarea liniară poate fi reprezentată ca fiind O(n) și O(log n) pentru căutarea binară (unde n și log(n) reprezintă numărul de operații).
Complexitatea în timp sau notațiile Big O pentru unii algoritmi populari sunt enumerate mai jos:
*Căutare binară: O(log n)
*Căutare liniară: O(n)
*Quick Sort: O(n * log n)
*Selection Sort: O(n * n)
*Vânzătorul ambulant : O(n!)
Concluzie
Știm că, pentru un număr mic de elemente (să zicem 10), diferența dintre numărul de operații efectuate de căutarea binară și căutarea liniară nu este atât de mare. Dar, în lumea reală, de cele mai multe ori, avem de-a face cu probleme care au bucăți mari de date.
De exemplu, dacă avem de căutat 4 miliarde de elemente, atunci, în cel mai rău caz, căutarea liniară va necesita 4 miliarde de operații pentru a-și îndeplini sarcina. Căutarea binară va finaliza această sarcină în doar 32 de operații. Aceasta este o diferență mare. Acum să presupunem că, dacă o operație durează 1 ms pentru finalizare, atunci căutarea binară va dura doar 32 ms, în timp ce căutarea liniară va dura 4 miliarde de ms (adică aproximativ 46 de zile). Aceasta este o diferență semnificativă.
Acesta este motivul pentru care studiul complexității timpului devine important atunci când este vorba de o cantitate atât de mare de date.
Pentru mai multe informatii puteti consulta articolele:
*https://www.freecodecamp.org/news/time-complexity-of-algorithms/
*https://www.youtube.com/watch?v=D6xkbGLQesk